



Bei der statistischen Analyse ist das Messniveau der Variablen entscheidend, da es die Art der möglichen Analyse beeinflusst. Nominale Daten sind am wenigsten detailliert, während Intervall- und Verhältnisdaten den höchsten Detaillierungsgrad aufweisen. Diese Unterschiede spiegeln die Unterschiede zwischen den vier primären Messebenen (nominal, ordinal, Intervall und Verhältnis) wider.
LERNEN ÜBER: Ebene der Analyse
Wenn Sie die Grundlagen der nominalen Daten verstehen möchten, sind Sie hier genau richtig. In diesem Blog gehen wir auf die Grundlagen dieser Datenanalyse ein, einschließlich dessen, was sie ist, wie man sie erkennt und einiger Beispiele.
Was sind Nominaldaten?
Nominale Daten sind „etikettierte“ oder „benannte“ Daten, die in verschiedene Gruppen eingeteilt werden können, die sich nicht überschneiden. In diesem Fall werden die Daten nicht gemessen oder bewertet, sondern lediglich mehreren Gruppen zugeordnet. Diese Gruppen sind eindeutig und haben keine gemeinsamen Elemente.
Die Reihenfolge der gesammelten Daten kann bei der Verwendung von nominalen Daten nicht festgelegt werden. Wenn Sie also die Reihenfolge der Daten ändern, ändert sich die Bedeutung der Daten nicht.
In der lateinischen Nomenklatur bedeutet „Nomen“ – Name. Nominale Daten weisen zwar eine Ähnlichkeit zwischen den verschiedenen Artikeln auf, aber Details zu dieser Ähnlichkeit werden möglicherweise nicht offengelegt. Dies dient lediglich dazu, die Datenerfassung und -analyse für die Forscher zu erleichtern. In einigen Fällen werden sie auch als „kategorische Daten“ bezeichnet.
Wenn binäre Daten „zweiwertige“ Daten darstellen, stellen diese Daten „mehrwertige“ Daten dar und können nicht quantitativ sein. Sie werden als diskret betrachtet. Zum Beispiel kann ein Hund ein Labrador sein oder nicht.
Erfahren Sie mehr über: Nominalskala
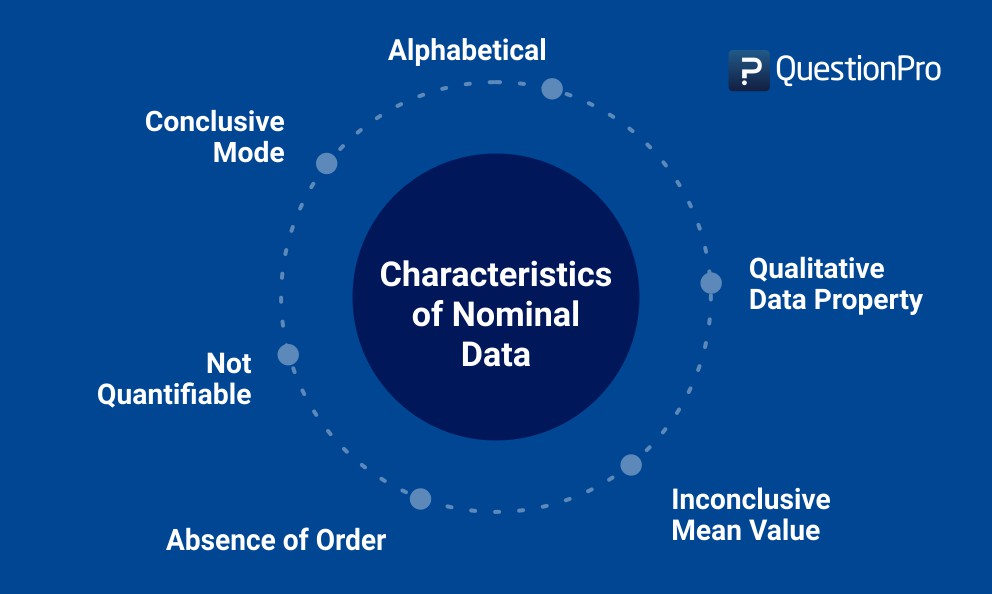
Merkmale von Nominaldaten
Lassen Sie uns anhand dieser Frage die Merkmale von nominalen Daten diskutieren:
- Q. Welcher Ethnie gehören Sie an?
- Zentralasiatisch
- Indonesisch
- Westasiatisch
- Japanisch
Seine wichtigsten Merkmale sind:
- Nominale Daten können niemals quantifiziert werden: Sie werden immer in Form von Nomenklatur vorliegen, d.h. eine Umfrage, die an asiatische Länder geschickt wird, kann eine Frage wie die in diesem Fall erwähnte enthalten.
Hier ist eine statistische, logische oder numerische Analyse der Daten nicht möglich, d.h. ein Forscher kann die gesammelten Daten nicht addieren, subtrahieren oder multiplizieren oder zu dem Schluss kommen, dass Variable 1 größer als Variable 2 ist. - Fehlen einer Ordnung: Im Gegensatz zu ordinalen Daten kann nominalen Daten auch nie eine bestimmte Reihenfolge zugewiesen werden. In dem obigen Beispiel ist die Reihenfolge der Antwortoptionen für die Antworten des Befragten irrelevant.
- Qualitative Eigenschaft: Die gesammelten Daten haben immer eine qualitative Eigenschaft – die Antwortmöglichkeiten sind mit hoher Wahrscheinlichkeit qualitativer Natur.
- Kann den Mittelwert nicht berechnen: Der Mittelwert kann nicht ermittelt werden, auch wenn die Daten in alphabetischer Reihenfolge angeordnet sind. In dem oben genannten Beispiel ist es für einen Forscher aufgrund des qualitativen Charakters der Optionen unmöglich, den Mittelwert der für die Ethnien eingereichten Antworten zu berechnen.
- Schließen Sie auf einen Modus: Wenn Sie eine große Gruppe von Personen nach ihren Präferenzen fragen, wird die häufigste Antwort der Modus sein. Wenn in diesem Beispiel Japanisch die Antwort ist, die von einem größeren Teil der Stichprobe gegeben wurde, dann ist dies der Modus.
- Daten sind meist alphabetisch: In den meisten Fällen sind nominale Daten alphabetisch und nicht numerisch – zum Beispiel in dem genannten Fall. Auch nicht-numerische Daten können in verschiedene Gruppen eingeteilt werden.
Erfahren Sie mehr: Quantitative Daten
Analyse nominaler Daten
Die meisten nominalen Daten werden über Fragen erhoben, bei denen der Befragte beispielsweise eine Liste von Elementen zur Auswahl hat:
- Q1. In welchem Staat leben Sie? ____ (gefolgt von einer Dropdown-Liste mit Staaten)
- Q2. Welche der folgenden Zutaten wählen Sie normalerweise für Ihren Pizzabelag? (Wählen Sie alle zutreffenden aus)
- Spinat
- Peperoni
- Oliven
- Sardinen
- Wurst
- Extra Käse
- Zwiebeln
- Tomaten
- Sonstiges (bitte angeben) _______________
Es gibt drei Möglichkeiten, wie nominale Daten erhoben werden können. Im ersten Beispiel erhält der Befragte Platz, um sein Heimatland einzutragen. Dies ist eine offene Frage, die schließlich kodiert wird, wobei jedem Bundesland eine Nummer zugewiesen wird. Diese Informationen könnten dem Befragten auch in Form einer Liste zur Verfügung gestellt werden, aus der er eine Option auswählen kann.
Das zweite Beispiel hat die Form von Multiple-Response-Fragen, bei denen jede Kategorie mit 1 (wenn ausgewählt) und 0 (wenn nicht ausgewählt) kodiert wird. Sie enthält auch eine offene Komponente, die dem Befragten die Möglichkeit gibt, eine Kategorie anzugeben, die nicht in der Liste enthalten ist. Diese „Andere (bitte angeben)“-Antworten müssen kodiert werden, wenn sie analysiert werden sollen.
Nominale Daten werden anhand von Prozentsätzen und dem „Modus“ analysiert, der die häufigste(n) Antwort(en) darstellt. Für eine bestimmte Frage kann es mehr als eine modale Antwort geben, zum Beispiel, wenn Oliven und Wurst gleich oft ausgewählt wurden.
Fragen mit mehreren Antwortmöglichkeiten, wie z.B. das oben genannte Beispiel mit dem Pizzabelag, ermöglichen es Forschern, eine metrische Variable zu erstellen, die für zusätzliche Analysen verwendet werden kann. In diesem Szenario kann der Befragte eine oder alle Optionen auswählen, so dass Sie eine Variable erhalten, die von Null (keine Auswahl) bis zur maximalen Anzahl von Kategorien reicht. Dies ist ein nützliches Instrument für die Segmentierung des Verbraucherverhaltens.
Erfahren Sie mehr: Marktsegmentierung

Deskriptive Statistik
Die Verteilung der Daten kann mithilfe der deskriptiven Statistik bestimmt werden. Wir können zwei Methoden der deskriptiven Statistik für diese Daten verwenden:
- Häufigkeitsverteilungstabelle: Sie dient dazu, nominale Daten in eine bestimmte Reihenfolge zu bringen. Anhand dieser Art von Tabelle können Sie leicht erkennen, wie viele Antworten es für jede Kategorie der Variable gab.
- Zentrale Tendenz: Dies ist allgemein als Modus bekannt. Er dient als Maß dafür, wo die meisten Werte liegen. Für diese Daten kann jedoch nur ein Modus geschätzt werden, da sie nur qualitativ sind.
LERNEN SIE ÜBER: Deskriptive Analyse
Grafische Analyse
Bei der grafischen Analyse werden die gesamten Daten in einem visuellen Format dargestellt. Wie bei der deskriptiven Statistik hilft Ihnen die Visualisierung Ihrer Daten, die Aussagekraft der Daten besser zu verstehen. Diese Methoden können sowohl auf den gesamten Datensatz in der Tabelle als auch auf eine Stichprobe davon angewendet werden.
- Balkendiagramm: Die Häufigkeit jeder Antwort wird in einem Balkendiagramm, das meist verwendet wird, als ein Balken dargestellt, der von der horizontalen Achse aus vertikal ansteigt. Die Höhe jedes Balkens steht in umgekehrter Beziehung zur Häufigkeit der jeweiligen Antwort.
- Kreisdiagramm: Die prozentuale Häufigkeit der einzelnen Stichproben des nominalen Datensatzes kann durch ein Tortendiagramm dargestellt werden, das ebenfalls verwendet wird.
Der Forscher verwendet in der Regel ein Tortendiagramm zur Darstellung von Prozentsätzen (oder Brüchen), während ein Balkendiagramm in der Regel zur Darstellung von Verteilungshäufigkeiten (Modus) verwendet wird.
Kategorisierung von Nominaldaten
Nominale Daten müssen auf der Grundlage von Ähnlichkeiten und Unterschieden kategorisiert werden, um richtig analysiert werden zu können. Bei dieser Methode können Forscher ihre Forschungsergebnisse vergleichen, indem sie sie mit einer ähnlichen Sammlung von Daten abgleichen, die noch nicht untersucht wurden.
- Abgestimmte Kategorie: Stichproben aus demselben nominalen Datensatz werden in der angepassten Kategorie gruppiert. Bessere statistische Ergebnisse sind das Hauptziel des Matchings, das durch die Reduzierung des Einflusses von Störfaktoren erreicht wird.
- Nicht übereinstimmende Kategorie: Nicht übereinstimmende Stichproben enthalten Variablen, die nicht miteinander verbunden sind. Es handelt sich um eine zufällige Auswahl aus mehreren verschiedenen Datensätzen ohne Gemeinsamkeiten.
Statistische Tests
Statistische Tests ermöglichen es Ihnen, eine Hypothese zu testen, indem Sie tiefer in die Informationen eindringen, die die Daten offenbaren, während deskriptive Statistiken, grafische Analysen und Kategorisierungen die nominalen Daten nur für eine einfache Analyse zusammenfassen. Bei der statistischen Analyse ist die Unterscheidung zwischen kategorischen Daten und numerischen Daten von entscheidender Bedeutung, da kategorische Daten eindeutige Kategorien oder Bezeichnungen beinhalten, während numerische Daten aus messbaren Größen bestehen.
Für nominale und ordinale Daten werden nicht-parametrische statistische Tests verwendet. Daher können Sie den beliebten Chi-Quadrat-Test durchführen, wenn Sie einen nominalen Datensatz untersuchen:
- Chi-Quadrat-Test der Anpassungsgüte: Mit diesem Test wird ermittelt, ob die Datenstichprobe typisch für die gesamte Datenpopulation ist. Der Test wird angewandt, wenn die Informationen über eine Zufallsstichprobe aus einer einzigen Grundgesamtheit gesammelt werden.
- Chi-Quadrat Unabhängigkeitstest: Damit wird die Beziehung zwischen zwei nominalen Variablen untersucht. Der Hypothesentest ermöglicht es, die Unabhängigkeit von zwei nominalen Variablen anhand einer einzigen Stichprobe zu bestimmen.
Beispiele für nominale Daten
In jedem der unten aufgeführten Beispiele sind den einzelnen Antwortmöglichkeiten Bezeichnungen zugeordnet, die lediglich der Kennzeichnung dienen. In der ersten Frage sind beispielsweise jeder Hunderasse Nummern zugeordnet, während in der zweiten Frage beiden Geschlechtern nur der Einfachheit halber entsprechende Initialen zugeordnet sind.
- Q1. In den USA gibt es eine große Gruppe von Menschen, die Hunde lieben und besitzen. Für ein Unternehmen, das sich um die Betreuung von Hunden kümmert, während die Besitzer abwesend sind, kann eine Frage wie diese nützlich sein, um den Zielmarkt zu filtern: Welches ist die beliebteste Hunderasse?
- Dalmatiner – 1
- Dobermann – 2
- Labrador – 3
- Deutscher Schäferhund – 4
- Q2. Für ein Reisebüro, das einen Reiseplan nur für eine bestimmte Gruppe von Personen erstellen möchte, ist dies die wichtigste Frage: Wer reist am liebsten?
- Männer – M
- Frauen – W
- Q3. Ein Immobilienmakler mit Sitz in New York wird die Antwort auf diese Frage sehr gut verstehen: Welche Art von Häusern wird von den Einwohnern von New York City bevorzugt?
- Wohnungen – A
- Bungalows – B
- Villen – C
Erfahren Sie mehr über: Arten von variablen Messskalen
QuestionPro Research Suite für die Erhebung und Analyse nominaler Daten verwenden
QuestionPro Research Suite ist eine Plattform für Umfragen und Untersuchungen, mit der Sie nominale Daten untersuchen können. Die Plattform bietet zahlreiche Funktionen und Tools für die Datenanalyse, wie z.B.:
- Fragetypen: In QuestionPro stehen Fragetypen zur Verfügung, darunter Fragen mit einfacher Auswahl, Fragen mit Mehrfachauswahl und offene Fragen, mit denen Sie nominale Daten erfassen können.
- Datenerhebung: QuestionPro bietet eine Vielzahl von Möglichkeiten zur Datenerhebung, darunter Internetumfragen, E-Mail-Einladungen und mobile Umfragen.
- Datenvisualisierung: Die Plattform bietet interaktive Datenvisualisierungsmöglichkeiten wie Torten- und Balkendiagramme.
- Datenanalyse: Das in QuestionPro eingebaute Modul zur Datenuntersuchung bietet deskriptive Statistiken für die Analyse von nominalen Daten, einschließlich Häufigkeits- und Prozentverteilung.
- Segmentierung: Die Plattform verfügt über Segmentierungsfunktionen, mit denen Benutzer nominale Daten in Gruppen einteilen können, die auf verschiedenen demografischen, verhaltensbezogenen oder psychografischen Merkmalen basieren.
- Berichte: QuestionPro bietet anpassbare Berichte, um die Ergebnisse zusammenzufassen und mit Entscheidungsträgern zu teilen.
Nutzen Sie die QuestionPro Research Suite, um nominale Daten zu sammeln und zu analysieren, um mehr über Ihr Publikum zu erfahren. Mit unserer Plattform können Sie demografische Online-Umfragen erstellen und verteilen, um Alter, Geschlecht, Ausbildung, Beruf und mehr zu erfassen. Unsere Datenvisualisierungstools und das Datenanalysemodul helfen Ihnen bei der sofortigen Interpretation der Ergebnisse.
LERNEN SIE MEHR: Durchschnittlicher Bestellwert
Nutzen Sie diese Chance, um Ihre Recherchefähigkeiten zu verbessern und Ihre Ziele zu erreichen. Beginnen Sie Ihre Reise durch die nominale Datenanalyse gleich mit einer kostenlosen Testversion!



