



Nell’analisi statistica, il livello di misurazione delle variabili è fondamentale perché influenza il tipo di analisi possibile. I dati nominali forniscono la quantità minore di dettagli, mentre quelli a intervalli e rapporti forniscono il livello di dettaglio più elevato; queste differenze riflettono le differenze tra i quattro livelli primari di misurazione (nominale, ordinale, a intervalli e a rapporti).
IMPARARE SU: Livello di analisi
Per comprendere i fondamenti dei dati nominali, questo è il posto giusto. In questo blog, esamineremo le basi di quest’analisi dei dati, tra cui cos’è, come identificarla e alcuni esempi.
Cosa sono i dati nominali?
I dati nominali sono dati “etichettati” o “nominati” che possono essere suddivisi in vari gruppi che non si sovrappongono. In questo caso i dati non vengono misurati o valutati, ma solo assegnati a più gruppi. Questi gruppi sono unici e non hanno elementi in comune.
L’ordine dei dati raccolti non può essere stabilito utilizzando dati nominali; pertanto, se si cambia l’ordine dei dati, il significato dei dati non viene alterato.
Nella nomenclatura latina, “Nomen” significa “Nome”. I dati nominali presentano una somiglianza tra i vari elementi, ma i dettagli relativi a tale somiglianza potrebbero non essere resi noti. Questo solo per facilitare il processo di raccolta e analisi dei dati da parte dei ricercatori. In alcuni casi si parla anche di “dati categorici”.
Se i dati binari rappresentano dati “a due valori”, questi dati rappresentano dati “a più valori” e non possono essere quantitativi. È considerato discreto. Ad esempio, un cane può essere un Labrador o meno.
Informazioni su: Scala nominale
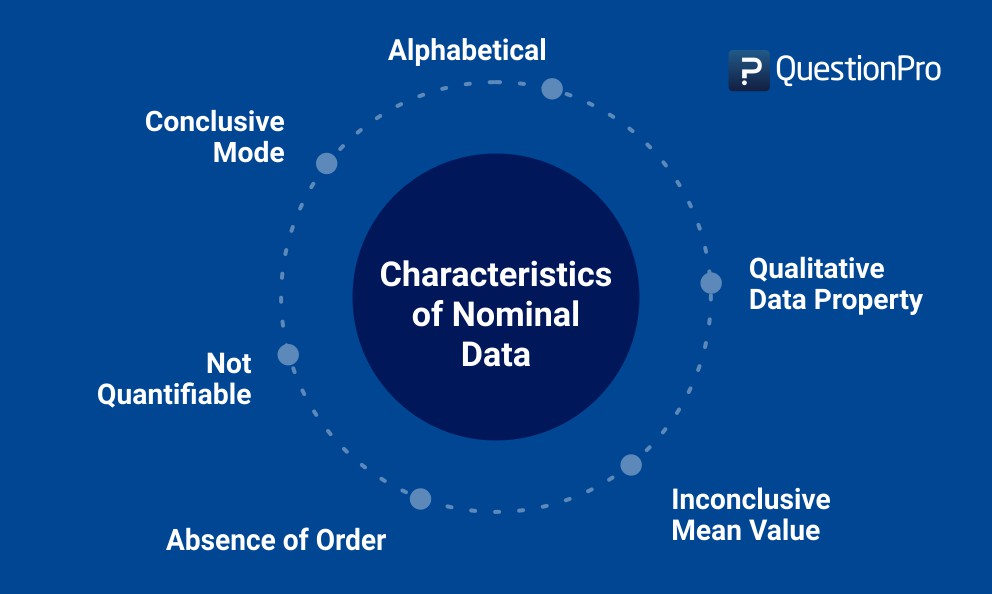
Caratteristiche dei dati nominali
Discutiamo le caratteristiche dei dati nominali utilizzando questa domanda:
- Q. Qual è la sua etnia?
- Asia centrale
- Indonesiano
- Asia occidentale
- Giapponese
Le sue caratteristiche principali sono:
- I dati nominali non possono mai essere quantificati: Si presenteranno sempre sotto forma di nomenclatura, cioè un sondaggio inviato ai Paesi asiatici può includere una domanda come quella citata in questo caso.
In questo caso, l’analisi statistica, logica o numerica dei dati non è possibile, vale a dire che il ricercatore non può sommare, sottrarre o moltiplicare i dati raccolti o concludere che la variabile 1 è maggiore della variabile 2. - Assenza di ordine: A differenza dei dati ordinali, ai dati nominali non può essere assegnato un ordine preciso. Nell’esempio precedente, l’ordine delle opzioni di risposta è irrilevante per le risposte fornite dall’intervistato.
- Proprietà qualitativa: I dati raccolti avranno sempre una proprietà qualitativa: è molto probabile che le opzioni di risposta siano di natura qualitativa.
- Non è possibile calcolare la media: Non è possibile stabilire la media anche se i dati sono disposti in ordine alfabetico. Nell’esempio sopra citato, è impossibile per un ricercatore calcolare la media delle risposte presentate per etnia a causa della natura qualitativa delle opzioni.
- Concludere una modalità: Chiedendo a un ampio campione di individui di esprimere le proprie preferenze, la risposta più comune sarà la modalità. Nell’esempio fornito, se il giapponese è la risposta presentata da una sezione più ampia di un campione, sarà la modalità.
- I dati sono per lo più alfabetici: nella maggior parte dei casi, i dati nominali sono alfabetici e non numerici, come nel caso citato. Anche i dati non numerici possono essere suddivisi in vari gruppi.
Analisi dei dati nominali
La maggior parte dei dati nominali viene raccolta tramite domande che forniscono all’intervistato un elenco di voci tra cui scegliere, ad esempio:
- Q1. In quale Stato vive? ____ (seguito da un elenco a discesa di stati)
- Q2. Quali dei seguenti elementi sceglie normalmente per i condimenti della pizza? (Selezionare tutte le opzioni)
- Spinaci
- Salame piccante
- Olive
- Sardine
- Salsiccia
- Formaggio extra
- Cipolle
- Pomodori
- Altro (specificare) _______________
I dati nominali possono essere raccolti in tre modi. Nel primo esempio, l’intervistato ha a disposizione uno spazio per scrivere il proprio stato di residenza. Si tratta di una domanda aperta che alla fine verrà codificata e a ogni Stato verrà assegnato un numero. Queste informazioni potrebbero anche essere fornite all’intervistato sotto forma di elenco, in cui selezionare un’opzione.
Il secondo esempio è sotto forma di domande a risposta multipla in cui ogni categoria è codificata con 1 (se selezionata) e 0 se non selezionata. Inoltre, incorpora una componente aperta che consente all’intervistato di scrivere in una categoria non inclusa nell’elenco. Le risposte “Altro (specificare)” dovranno essere codificate per essere analizzate.
I dati nominali vengono analizzati utilizzando le percentuali e la “modalità”, che rappresenta la risposta più comune. Per una data domanda, può esserci più di una risposta modale, ad esempio se le olive e la salsiccia sono state selezionate lo stesso numero di volte.
Le domande a risposta multipla, come l’esempio del condimento della pizza, consentono ai ricercatori di creare una variabile metrica che può essere utilizzata per ulteriori analisi. In questo scenario, l’intervistato può selezionare una o tutte le opzioni, fornendo una variabile che va da zero (nessuno selezionato) al numero massimo di categorie. Questo diventa uno strumento utile per la segmentazione comportamentale dei consumatori.

Statistiche descrittive
La distribuzione dei dati può essere determinata utilizzando le statistiche descrittive. Per questi dati possiamo utilizzare due metodi di statistica descrittiva:
- Tabella di distribuzione di frequenza: È progettata per organizzare i dati nominali in un certo ordine. Questo tipo di tabella permette di vedere facilmente quante risposte ci sono state per ogni categoria della variabile.
- Tendenza centrale: È comunemente nota come modalità. Serve a misurare dove si trova la maggioranza dei valori. Tuttavia, per questi dati è possibile stimare solo una modalità, perché è solo qualitativa.
Analisi grafica
L’analisi grafica prevede la presentazione dell’insieme dei dati in un formato visivo. Come per le statistiche descrittive, la visualizzazione dei dati aiuta a capire meglio ciò che essi dicono. Questi metodi possono essere utilizzati sull’intero set di dati della tabella e su un campione estratto da esso.
- Grafico a barre: La frequenza di ogni risposta è rappresentata graficamente come una barra che sale verticalmente dall’asse orizzontale in un grafico a barre, che è il più utilizzato. L’altezza di ogni barra è inversamente correlata alla frequenza della risposta in questione.
- Grafico a torta: La frequenza percentuale di ciascun campione dell’insieme di dati nominali può essere rappresentata da un grafico a torta.
Il ricercatore utilizza in genere un grafico a torta per rappresentare le percentuali (o frazioni), mentre un grafico a barre viene utilizzato per rappresentare le frequenze di distribuzione (modalità).
Categorizzazione dei dati nominali
I dati nominali richiedono una categorizzazione basata su somiglianze e differenze per essere analizzati correttamente. Con questo metodo, i ricercatori possono confrontare i risultati delle loro ricerche abbinandoli a una raccolta di dati simili che non sono stati analizzati.
- Categoria abbinata: I campioni dello stesso set di variabili di dati nominali vengono raggruppati nella categoria abbinata. Il miglioramento dei risultati statistici è l’obiettivo principale del matching, che si ottiene riducendo l’influenza dei fattori confondenti.
- Categoria non abbinata: I campioni non abbinati contengono variabili non collegate tra loro. Si tratta di una selezione casuale da diversi set di dati senza alcun punto in comune.
Test statistici
I test statistici consentono di verificare un’ipotesi approfondendo le informazioni che i dati rivelano, mentre le statistiche descrittive, l’analisi grafica e la categorizzazione si limitano a riassumere i dati nominali per un’analisi diretta. Nell’analisi statistica, la distinzione tra dati categorici e dati numerici è essenziale, poiché i dati categorici comportano categorie o etichette distinte, mentre i dati numerici consistono in quantità misurabili.
Per i dati nominali e ordinali si utilizzano test statistici non parametrici. Pertanto, è possibile eseguire il famoso test del Chi-quadro quando si esamina un insieme di dati nominali:
- Test di bontà del Chi-quadro: Questo test determina se il campione di dati è tipico dell’intera popolazione di dati. Il test si applica quando le informazioni sono raccolte tramite un campionamento casuale da un’unica popolazione.
- Test di indipendenza chi-quadro: Esamina la relazione tra due variabili nominali. La verifica delle ipotesi consente di determinare l’indipendenza di due variabili nominali da un unico campione.
Esempi di dati nominali
In ciascuno dei seguenti esempi, le etichette sono associate a ciascuna opzione di risposta solo a scopo di etichettatura. Per esempio, nella prima domanda a ogni razza di cane vengono assegnati dei numeri, mentre nella seconda domanda a entrambi i sessi vengono assegnate le iniziali corrispondenti solo per comodità.
- Q1. Negli Stati Uniti c’è un’enorme fetta di persone che amano e possiedono cani. Per un’azienda che si occupa di accudire i cani quando i proprietari non ci sono, una domanda come questa può essere utile per filtrare il proprio mercato di riferimento: Qual è la razza di cani più amata?
- Dalmata – 1
- Dobermann – 2
- Labrador – 3
- Pastore tedesco – 4
- Q2. Per un’agenzia di viaggi che voglia lanciare un piano di viaggio esclusivamente per un campione di persone, questa è la domanda più elementare: Chi ama di più viaggiare?
- Uomini – M
- Donne – W
- Q3. Un agente immobiliare con sede a New York sarà molto propenso a capire la risposta a questa domanda: Quale tipo di case sono preferite dai residenti di New York?
- Appartamenti – A
- Bungalow – B
- Ville – C
Utilizzo di QuestionPro Research Suite per la raccolta e l’analisi dei dati nominali
QuestionPro Research Suite è una piattaforma per sondaggi e ricerche che può essere utilizzata per esaminare dati nominali. La piattaforma offre numerose funzionalità e strumenti per l’analisi dei dati, quali:
- Tipi di domande: I tipi di domande, tra cui quelle a selezione singola, multipla e aperta, sono disponibili in QuestionPro e possono essere utilizzati per raccogliere dati nominali.
- Raccolta dati: QuestionPro offre una serie di opzioni di raccolta dati, tra cui sondaggi via Internet, inviti via e-mail e sondaggi mobili.
- Visualizzazione dei dati: La piattaforma offre scelte interattive per la visualizzazione dei dati, come grafici a torta e a barre.
- Analisi dei dati: Il modulo di analisi dei dati integrato in QuestionPro offre statistiche descrittive per l’analisi dei dati nominali, comprese le distribuzioni di frequenza e percentuale.
- Segmentazione: La piattaforma dispone di funzioni di segmentazione che consentono agli utenti di suddividere i dati nominali in gruppi basati su vari tratti di segmentazione demografica, comportamentale o psicografica.
- Rapporti: QuestionPro offre rapporti personalizzabili per riassumere e condividere i risultati con i responsabili delle decisioni.
Utilizzate QuestionPro Research Suite per raccogliere e analizzare i dati nominali e conoscere il vostro pubblico. La nostra piattaforma consente di creare e distribuire sondaggi demografici online per raccogliere età, sesso, istruzione, occupazione e altro ancora. I nostri strumenti di visualizzazione dei dati e il modulo di analisi dei dati vi aiuteranno a interpretare immediatamente i risultati.
Cogliete questa occasione per migliorare le vostre capacità di ricerca e raggiungere i vostri obiettivi. Iniziate subito il vostro viaggio nell’analisi dei dati nominali con una prova gratuita!



