



Bij statistische analyse is het meetniveau van variabelen cruciaal, omdat het van invloed is op het type analyse dat mogelijk is. Nominale gegevens geven de kleinste mate van detail, terwijl interval- en ratiogegevens de grootste mate van detail geven; deze verschillen weerspiegelen de verschillen tussen de vier primaire meetniveaus (nominaal, ordinaal, interval en ratio).
LEER OVER: Analyseniveau
Om de grondbeginselen van nominale gegevens te begrijpen, moet je hier zijn. In deze blog bespreken we de basisprincipes van deze gegevensanalyse, inclusief wat het is, hoe je het identificeert en enkele voorbeelden.
Wat zijn nominale gegevens?
Nominale gegevens zijn “gelabelde” of “benoemde” gegevens die kunnen worden onderverdeeld in verschillende groepen die elkaar niet overlappen. Gegevens worden in dit geval niet gemeten of geëvalueerd; ze worden gewoon toegewezen aan meerdere groepen. Deze groepen zijn uniek en hebben geen gemeenschappelijke elementen.
De volgorde van de verzamelde gegevens kan niet worden vastgesteld met behulp van nominale gegevens; dus als je de volgorde van de gegevens verandert, zal de betekenis van de gegevens niet veranderen.
In Latijnse nomenclatuur betekent “Nomen” – Naam. Nominale gegevens laten wel een overeenkomst zien tussen de verschillende items, maar details over deze overeenkomst worden mogelijk niet bekendgemaakt. Dit is alleen bedoeld om het verzamelen en analyseren van gegevens gemakkelijker te maken voor onderzoekers. In sommige gevallen worden ze ook wel “Categorische gegevens” genoemd.
Als binaire gegevens gegevens van “twee waarden” vertegenwoordigen, dan vertegenwoordigen deze gegevens gegevens van “meerdere waarden” en kunnen ze niet kwantitatief zijn. Het wordt beschouwd als discreet. Een hond kan bijvoorbeeld een Labrador zijn of niet.
Leer meer over: Nominale schaal
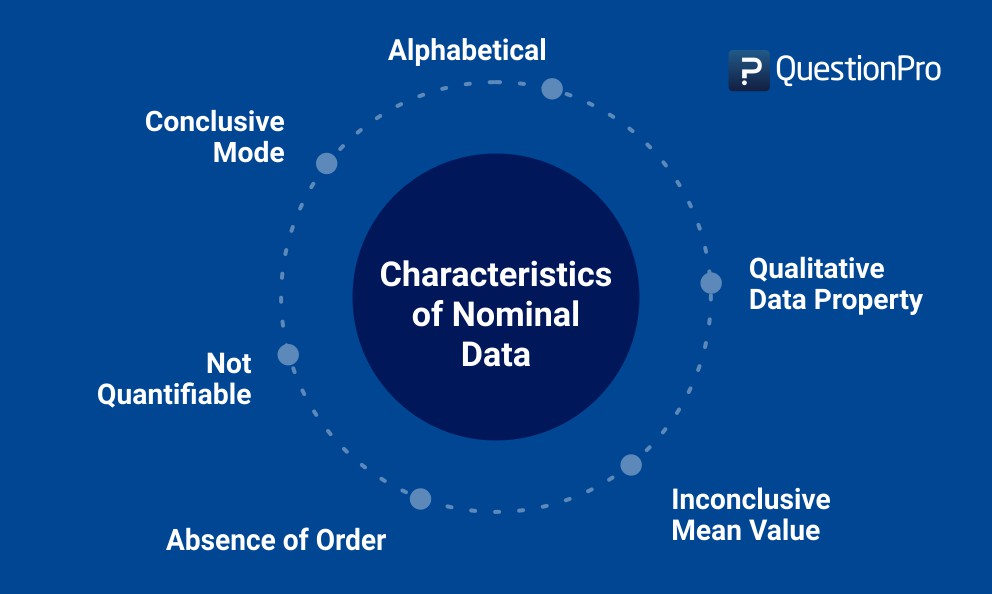
Kenmerken van nominale gegevens
Laten we de kenmerken van nominale gegevens bespreken aan de hand van deze vraag:
- Q. Wat is uw etniciteit?
- Centraal-Aziatisch
- Indonesisch
- West-Aziatisch
- Japans
De belangrijkste kenmerken zijn:
- Nominale gegevens kunnen nooit worden gekwantificeerd: Het zal altijd in de vorm van nomenclatuur zijn, d.w.z. een enquête die naar Aziatische landen wordt gestuurd kan een vraag bevatten zoals de vraag die in dit geval wordt genoemd.
Hier is geen statistische, logische of numerieke analyse van gegevens mogelijk, d.w.z. een onderzoeker kan de verzamelde gegevens niet optellen, aftrekken of vermenigvuldigen of concluderen dat variabele 1 groter is dan variabele 2. - Afwezigheid van volgorde: In tegenstelling tot ordinale gegevens, kan aan nominale gegevens ook nooit een bepaalde volgorde worden toegekend. In het bovenstaande voorbeeld is de volgorde van de antwoordopties niet relevant voor de antwoorden van de respondent.
- Kwalitatieve eigenschap: Verzamelde gegevens hebben altijd een kwalitatieve eigenschap – antwoordopties zijn hoogstwaarschijnlijk kwalitatief van aard.
- Kan gemiddelde niet berekenen: Het gemiddelde kan niet worden vastgesteld, zelfs niet als de gegevens op alfabetische volgorde zijn gerangschikt. In het bovenstaande voorbeeld is het voor een onderzoeker onmogelijk om het gemiddelde te berekenen van de antwoorden die zijn ingediend voor etniciteiten vanwege de kwalitatieve aard van de opties.
- Een modus concluderen: Als je een grote steekproef van individuen vraagt om hun voorkeuren in te dienen, zal het meest voorkomende antwoord de modus zijn. In het gegeven voorbeeld, als Japans het antwoord is dat is ingediend door een groter deel van een steekproef, zal het de modus zijn.
- Gegevens zijn meestal alfabetisch: In de meeste gevallen zijn nominale gegevens alfabetisch en niet numeriek – bijvoorbeeld in het genoemde geval. Niet-numerieke gegevens kunnen ook worden ingedeeld in verschillende groepen.
Meer informatie: Kwantitatieve gegevens
Analyse van nominale gegevens
De meeste nominale gegevens worden verzameld via vragen waarbij de respondent bijvoorbeeld een lijst met items krijgt om uit te kiezen:
- Q1. In welke staat woon je? ____ (gevolgd door een vervolgkeuzelijst met staten)
- Q2. Welke van de volgende items kies je normaal als beleg op je pizza? (Selecteer alles wat van toepassing is)
- Spinazie
- Pepperoni
- Olijven
- Sardientjes
- Worst
- Extra kaas
- Uien
- Tomaten
- Andere (geef aan welke) _______________
Er zijn drie manieren waarop nominale gegevens verzameld kunnen worden. In het eerste voorbeeld krijgt de respondent ruimte om zijn thuisstaat in te vullen. Dit is een open vraag die uiteindelijk zal worden gecodeerd, waarbij elke staat een nummer krijgt toegewezen. Deze informatie kan ook in de vorm van een lijst aan de respondent worden gegeven, waarbij hij of zij een optie selecteert.
Het tweede voorbeeld heeft de vorm van meerkeuzevragen waarbij elke categorie gecodeerd wordt met 1 (indien geselecteerd) en 0 indien niet geselecteerd. Het bevat ook een open einde component waardoor de respondent de mogelijkheid heeft om in een categorie te schrijven die niet in de lijst voorkomt. Deze “Andere (geef aan welke)” antwoorden moeten gecodeerd worden om ze te kunnen analyseren.
Nominale gegevens worden geanalyseerd met behulp van percentages en de ‘modus’, die de meest voorkomende respons(en) weergeeft. Voor een bepaalde vraag kan er meer dan één modaal antwoord zijn, bijvoorbeeld als olijven en worst allebei even vaak werden gekozen.
Meervoudige antwoordvragen, zoals het voorbeeld van de pizzatopping hierboven, geven onderzoekers de mogelijkheid om een metrische variabele te maken die gebruikt kan worden voor aanvullende analyse. In dit scenario kan de respondent alle opties selecteren, waardoor je een variabele krijgt die varieert van nul (geen enkele geselecteerd) tot het maximale aantal categorieën. Dit wordt een nuttig hulpmiddel voor gedragssegmentatie van consumenten.
Meer informatie: Marktsegmentatie

Beschrijvende Statistieken
De verdeling van de gegevens kan worden bepaald met behulp van beschrijvende statistieken. We kunnen twee beschrijvende statistische methoden gebruiken voor deze gegevens:
- Frequentieverdelingstabel: Deze is bedoeld om nominale gegevens in een bepaalde volgorde te ordenen. Dit soort tabel maakt het gemakkelijk om te zien hoeveel antwoorden er waren voor elke categorie in de variabele.
- Centrale tendens: Dit is algemeen bekend als een modus. Het dient als maatstaf voor waar de meerderheid van de waarden zich bevindt. Er kan echter maar één modus worden geschat voor deze gegevens omdat ze alleen kwalitatief zijn.
LEER OVER: Beschrijvende analyse
Grafische analyse
Bij de grafische analyse worden alle gegevens visueel weergegeven. Net als beschrijvende statistieken helpt het visualiseren van je gegevens je om gemakkelijker te zien wat de gegevens vertellen. Deze methoden kunnen worden toegepast op de volledige gegevensreeks in de tabel en op een steekproef daaruit.
- Staafdiagram: De frequentie van elke respons wordt grafisch voorgesteld als een staaf die verticaal oploopt vanaf de horizontale as in een staafdiagram, dat meestal wordt gebruikt. De hoogte van elke balk is omgekeerd evenredig met de frequentie van het betreffende antwoord.
- Taartdiagram: De procentuele frequentie van elk monster van de nominale dataset kan worden weergegeven door een taartdiagram, dat ook wordt gebruikt.
De onderzoeker gebruikt meestal een taartdiagram om percentages (of fracties) weer te geven, terwijl een staafdiagram meestal wordt gebruikt om distributiefrequenties (modus) weer te geven.
Categorisering van nominale gegevens
Om nominale gegevens goed te kunnen analyseren, moeten ze worden gecategoriseerd op basis van overeenkomsten en verschillen. Bij deze methode kunnen onderzoekers hun onderzoeksresultaten vergelijken door ze te vergelijken met een vergelijkbare verzameling gegevens die nog niet onderzocht is.
- Gematchte categorie: Monsters van dezelfde set nominale gegevensvariabelen worden gegroepeerd in de gematchte categorie. Verbeterde statistische resultaten zijn het primaire doel van matching, wat wordt bereikt door de invloed van verstorende factoren te verminderen.
- Niet-afgestemde categorie: Unmatched samples bevatten variabelen die niet met elkaar verbonden zijn. Het is een willekeurige selectie uit verschillende datasets zonder overeenkomsten.
Statistische tests
Met statistische tests kun je een hypothese testen door dieper in te gaan op de informatie die de gegevens onthullen, terwijl beschrijvende statistieken, grafische analyse en categorisatie alleen de nominale gegevens samenvatten voor een eenvoudige analyse. Bij statistische analyse is het essentieel om onderscheid te maken tussen categorische gegevens en numerieke gegevens, omdat categorische gegevens verschillende categorieën of labels bevatten, terwijl numerieke gegevens bestaan uit meetbare grootheden.
Voor nominale en ordinale gegevens worden niet-parametrische statistische toetsen gebruikt. Daarom kun je de populaire Chi-kwadraattest uitvoeren als je een nominale dataset onderzoekt:
- Chi-kwadraat goodness of fit-test: Deze test bepaalt of de steekproef van gegevens typerend is voor de gehele populatie van gegevens. De test wordt toegepast wanneer informatie wordt verzameld via aselecte steekproeven uit een enkele populatie.
- Chi-kwadraat onafhankelijkheidstest: Hiermee wordt de relatie tussen twee nominale variabelen onderzocht. Het testen van hypothesen maakt het mogelijk om de onafhankelijkheid van twee nominale variabelen uit een enkele steekproef te bepalen.
Voorbeelden van nominale gegevens
In elk van de onderstaande voorbeelden zijn er labels gekoppeld aan elk van de antwoordopties, alleen voor het labelen. In de eerste vraag krijgt elk hondenras bijvoorbeeld een nummer toegewezen, terwijl in de tweede vraag beide geslachten voor het gemak overeenkomstige initialen krijgen.
- Q1. In de VS is er een grote groep mensen die van honden houdt en honden bezit. Voor een bedrijf dat zich bezighoudt met het verzorgen van honden terwijl de baasjes weg zijn, kan een vraag als deze nuttig zijn om hun doelmarkt te filteren: Wat is het meest geliefde hondenras?
- Dalmatiër – 1
- Doberman – 2
- Labrador – 3
- Duitse herder – 4
- Q2. Voor een reisbureau dat een reisplan wil lanceren puur voor een steekproef van individuen, is dit de meest elementaire vraag: Wie houdt er meer van reizen?
- Heren – M
- Vrouwen – W
- Q3. Een makelaar uit New York zal zeer geneigd zijn om het antwoord op deze vraag te begrijpen: Aan welk type huizen geven de inwoners van New York de voorkeur?
- Appartementen – A
- Bungalows – B
- Villa’s – C
Leer meer over: Soorten variabele meetschalen
QuestionPro Research Suite gebruiken voor het verzamelen en analyseren van nominale gegevens
QuestionPro Research Suite is een platform voor enquêtes en onderzoek dat kan worden gebruikt om nominale gegevens te onderzoeken. Het platform biedt tal van functies en tools voor gegevensanalyse, zoals:
- Vraagtypen: Vraagtypen, waaronder enkelvoudige, meervoudige en open vragen, zijn beschikbaar in QuestionPro en kunnen worden gebruikt om nominale gegevens te verzamelen.
- Gegevensverzameling: QuestionPro biedt verschillende opties voor gegevensverzameling, waaronder internetenquêtes, uitnodigingen per e-mail en mobiele enquêtes.
- Visualisatie van gegevens: Het platform biedt interactieve datavisualisatiemogelijkheden zoals cirkeldiagrammen en staafdiagrammen.
- Gegevensanalyse: De ingebouwde module voor gegevensonderzoek in QuestionPro biedt beschrijvende statistieken voor de analyse van nominale gegevens, inclusief frequentie- en percentageverdeling.
- Segmentatie: Het platform heeft segmentatiefuncties waarmee gebruikers nominale gegevens kunnen verdelen in groepen op basis van verschillende demografische, gedrags- of psychografische segmentatiekenmerken.
- Rapporten: QuestionPro biedt aanpasbare rapporten voor het samenvatten en delen van bevindingen met besluitvormers.
Gebruik QuestionPro Research Suite voor het verzamelen en analyseren van nominale gegevens om meer te weten te komen over uw publiek. Met ons platform kun je online demografische enquêtes maken en verspreiden om leeftijd, geslacht, opleiding, beroep en meer te verzamelen. Onze tools voor gegevensvisualisatie en gegevensanalysemodule helpen je om de resultaten onmiddellijk te interpreteren.
LEER OVER: Gemiddelde bestelwaarde
Grijp deze kans om je onderzoeksvaardigheden te verbeteren en je doelen te bereiken. Begin uw reis naar de analyse van nominale gegevens meteen met een gratis proefversie!



