



Als je met gegevens werkt, moet je bekend zijn met de vier belangrijkste gegevenstypen: nominaal, ordinaal, interval en ratio. Deze blog concentreert zich op ordinale gegevens. We definiëren, verkennen de kenmerken en geven voorbeelden van deze gegevens.
Lees verder om alles te weten te komen over deze gegevens, het gebruik, de analyse en het verschil tussen nominale en ordinale gegevens.
LEER OVER: Analyseniveau
Wat zijn ordinale gegevens?
Ordinale gegevens zijn een statistisch type kwantitatieve gegevens waarin variabelen bestaan in natuurlijk voorkomende geordende categorieën. Het kan echter niet worden gebruikt om de afstand tussen de twee categorieën te bepalen.
In de statistiek geeft een groep ordinale getallen dezegegevens aan, en een groep van deze gegevens wordt weergegeven met een ordinale schaal . Het belangrijkste verschil tussen ordinale en nominale gegevens is dat ordinaal een volgorde van categorieën heeft en nominaal niet.
Meer informatie: Nominale vs Ordinale schaal
Likert-schaal is een populair voorbeeld van deze gegevens. Voor een vraag zoals: “Gelieve aan te geven hoe belangrijk de prijs voor u is om een product te kopen.”, zal een Likertschaal de volgende opties hebben, die worden gecodeerd tot 1,2,3,4 en 5 (getallen). 1 is kleiner dan 2, wat kleiner is dan 3, wat kleiner is dan 4, wat op zijn beurt weer kleiner is dan 5.
| Zeer belangrijk | Belangrijk | Neutraal | Onbelangrijk | Zeer onbelangrijk |
| 1 | 2 | 3 | 4 | 5 |
Ordinale gegevens zijn dus een verzameling ordinale variabelen, d.w.z. als je variabelen in een bepaalde volgorde hebt – “laag, gemiddeld, hoog”, kunnen ze worden weergegeven als dit soort gegevens. Er zijn twee belangrijke factoren om rekening mee te houden bij deze gegevens:
- Meerdere termen staan voor “volgorde”, zoals “Hoog, Hoger, Hoogst” of “Tevreden, Ontevreden, Zeer Ontevreden”.
- Het verschil tussen variabelen is niet uniform.
Meer informatie: Soorten meetvariabelen
Gebruik van ordinale gegevens
Deze gegevens zijn een belangrijk gegevenstype op veel gebieden en worden veel gebruikt in onderzoek en praktijk. Hier bespreken we enkele belangrijke toepassingen van deze gegevens:
Enquêtes/vragenlijsten
Het wordt gebruikt voor enquêtes en vragenlijsten vanwege de “geordende” aard. Statistische analyse wordt gebruikt om reacties te verzamelen en de respondenten te categoriseren op basis van hun antwoorden. Bij statistische analyse is het essentieel om onderscheid te maken tussen categorische gegevens en numerieke gegevens, omdat categorische gegevens verschillende categorieën of labels bevatten, terwijl numerieke gegevens bestaan uit meetbare grootheden.
De inzichten van deze analyse worden gebruikt om gevolgtrekkingen te maken en conclusies te trekken over de respondenten in relatie tot specifieke variabelen. Het wordt hier vaak voor gebruikt omdat het gemakkelijk te categoriseren en te vergelijken is.
Onderzoek
Onderzoekers gebruiken dit soort gegevens om nuttige informatie te verzamelen over het onderwerp van hun onderzoek. Medische onderzoekers moeten bijvoorbeeld gegevens verzamelen wanneer ze de bijwerkingen van een medicijn onderzoeken dat aan 50 patiënten wordt gegeven.
Na het toedienen van de medicatie kan elke patiënt gevraagd worden een formulier in te vullen om aan te geven in hoeverre hij of zij bepaalde mogelijke bijwerkingen ervaart.
Klantenservice
Deze gegevens worden door bedrijven gebruikt om de algehele klantenservice te verbeteren. Wanneer klanten een dienst gebruiken of een product kopen van een bedrijf, worden ze vaak gevraagd om een formulier in te vullen over hun ervaring. Het zal bedrijven helpen om hun klantenservice te verbeteren.
Sollicitaties
Werkgevers zullen af en toe een Likert-schaal gebruiken bij het verzamelen van informatie van sollicitanten tijdens de sollicitatieprocedure. Als een sollicitant bijvoorbeeld solliciteert naar een functie als social media manager, kan een Likert-schaal worden gebruikt om te bepalen hoe bekend een sollicitant is met Facebook, Twitter, LinkedIn, enzovoort.
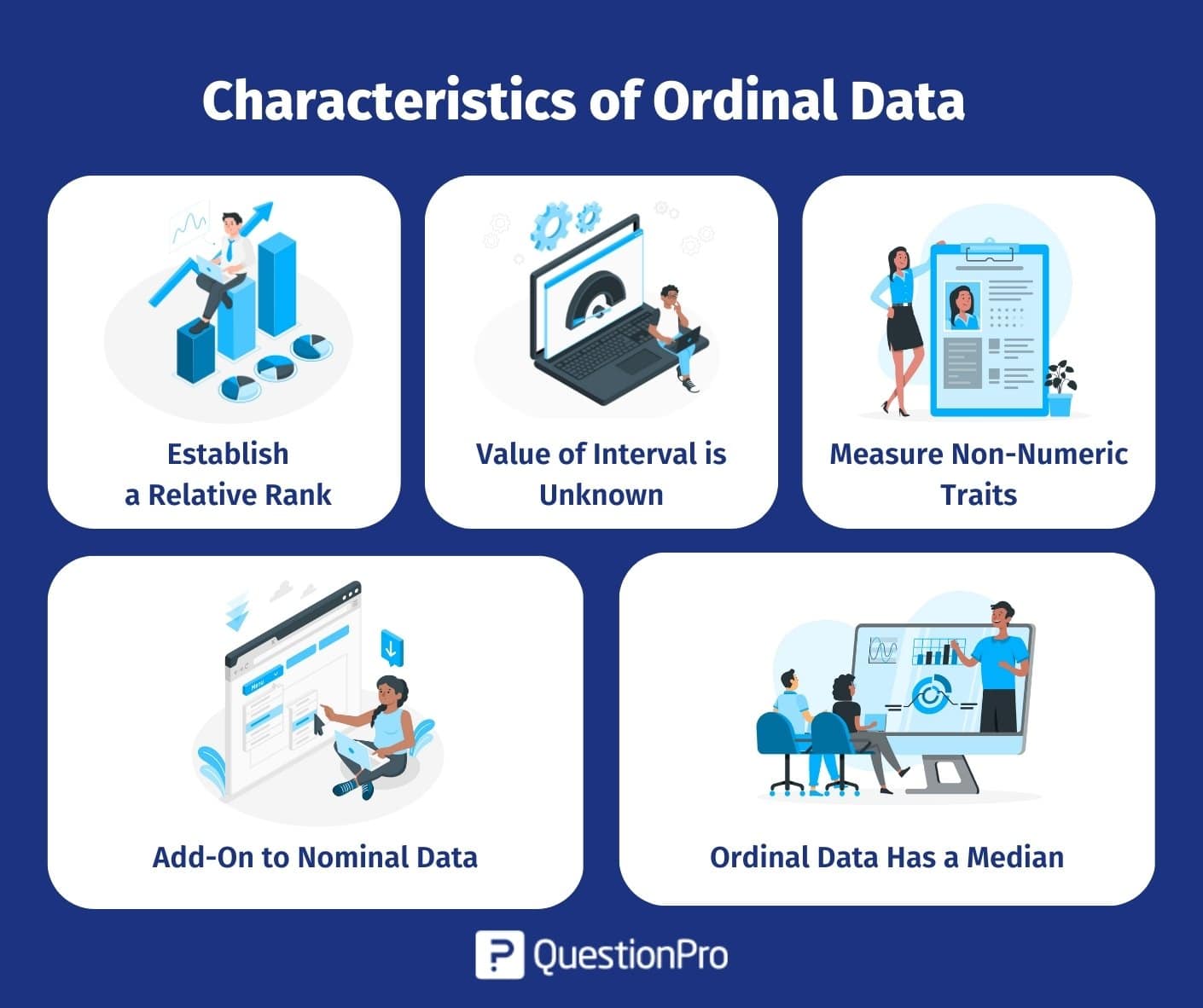
Kenmerken van ordinale gegevens
Hier volgen vijf kenmerken van dit soort gegevens:
- Welke categorieën beschrijven het best uw laatste aankoopervaring met een product/dienst?
- Zeer aangenaam
- Enigszins aangenaam
- Neutraal
- Enigszins onaangenaam
- Zeer onaangenaam
- Bepaal een relatieve rangorde: In het bovenstaande voorbeeld is Enigszins aangenaam zeker erger dan Zeer aangenaam, of Zeer onaangenaam is erger dan Enigszins onaangenaam. Er is duidelijk een rangorde binnen de opties – wat wijst op ditsoort gegevens.
- Waarde van interval is onbekend: De variatie tussen aangenaam en aangenaam is mogelijk niet hetzelfde als het verschil tussen enigszins onaangenaam en zeer onaangenaam. Je kunt dit interval niet opnemen met deze gegevens.
- Niet-numerieke eigenschappen meten: Alle antwoordopties in het vorige voorbeeld zijn niet-numeriek en deze gegevens kunnen worden gebruikt om gevoelens zoals tevredenheid, geluk, frequentie enzovoort vast te leggen.
- Toevoeging aan nominale gegevens: Nominale gegevens zijn “gelabelde” gegevens. It is gelabelde data in een specifieke volgorde. In het bovenstaande voorbeeld is er een opvallende volgorde in de opties, waardoor het een klassiek geval is van dit soort gegevens.
- Ordinale gegevens hebben een mediaan: De mediaan is de waarde in het midden van een schaal die niet de middelste waarde is, en het kan berekenen met gegevens die een inherente volgorde hebben.
Ordinale gegevensanalyse
Deze gegevensanalyse is een statistisch analyseplan voor het analyseren van gegevens met een natuurlijke volgorde of rangschikking. Dit soort gegevens wordt vaak verzameld via enquêtes of vragenlijsten. Laten we eens kijken hoe je je ordinale gegevens kunt analyseren:
- Eenvoudige methoden voor Ordinale gegevensanalyse
Deze gegevens worden in tabelvorm gepresenteerd om de analyse gemakkelijker maken voor de onderzoeker. Mozaïekplots leggen ook de relatie tussen nominale en ordinale gegevens.
Als een organisatie bijvoorbeeld van plan is om het aantal werknemers in elke hiërarchie te analyseren om een systematisch aanwervingsproces voor het komende jaar te maken, dan kunnen ze deze gegevens in een geordende tabelindeling zetten. HR-managers zullen deze gegevens zeer gemakkelijk kunnen raadplegen en analyseren voor eventuele toekomstige updates.
- Mann-Whitney U-test
De Mann-Whitney U-test is gebruikt om twee ordinale gegevensgroepen te vergelijken. Met deze test kan een onderzoeker concluderen dat een variabele uit een steekproef groter of kleiner is dan een andere variabele die willekeurig uit een andere steekproef is gekozen.
Psychologische onderzoekers kunnen bijvoorbeeld gedragspatronen bestuderen om twee verschillende medicijnen te vergelijken.
- Kruskal-Wallis H-test
Om meer dan twee groepen van deze gegevens te vergelijken Kruskal-Wallis H test moet worden gebruikt – Bij deze test is er geen aanname dat de gegevens van een bepaalde bron afkomstig zijn. Deze test bepaalt of de mediaan van twee of meer groepen gevarieerd is. Het toont het verschil tussen meer dan twee groepen van deze gegevens.
Een onderzoeker wil bijvoorbeeld de impact van stress op het werk op de kwaliteit van het werk evalueren. In dat geval, de onafhankelijke variabele is stress op het werk die idealiter drie stadia kent: geen stress, te veel stress en hanteerbare stress, en de kwaliteit van het werk varieert van slecht tot uitstekend.
Voorbeelden van ordinale gegevens
Het is een type categorische gegevens waarbij de categorieën een natuurlijke volgorde of rangorde hebben. Hier volgen enkele voorbeelden van dit soort gegevens:
- Op een school met 3000 leerlingen zijn er verschillende categorieën: eerstejaars, tweedejaars, junioren en senioren. Nadat de termijn is begonnen, is dit de telling van elke categorie :
- 1000 – Eerstejaars
- 800 – tweedejaars
- 750 – Junioren
- 450 – Senioren
- Een organisatie voert elk kwartaal een medewerkerstevredenheidsonderzoek uit met deze vraag: “Hoe tevreden ben je met je manager en collega’s?”
- Extreem gelukkig – 1
- Gelukkig – 2
- Neuraal – 3
- Ongelukkig – 4
- Extreem ongelukkig – 5
- Beoordeel deze 5 best verkochte boeken aan de hand van je voorkeuren:
- Vuur en woede – 1
- Een hogere loyaliteit: Waarheid, leugens en leiderschap – 2
- De vrouw in het raam – 3
- De Grote Alleen – 4
- De subtiele kunst van geen f*ck geven: Een contra-intuïtieve benadering van een goed leven – 5
Verschil tussen ordinale gegevens en nominale gegevens
Gegevens kunnen in de statistiek worden ingedeeld in verschillende typen op basis van hun kenmerken en eigenschappen. Ordinale gegevens en nominale gegevens zijn twee voorbeelden van dergelijke gegevens. Inzicht in het verschil tussen ordinale en nominale gegevens is belangrijk bij veel statistische analyses, omdat het bepaalt welke analysemethoden gebruikt moeten worden. Hier leren we enkele belangrijke verschillen tussen deze twee soorten gegevens:
- Nominale gegevens zijn gegevens die worden gecategoriseerd zonder een bepaalde volgorde of rangschikking. Haarkleur, geslacht en type auto zijn bijvoorbeeld allemaal voorbeelden van nominale gegevens. Ordinale gegevens daarentegen zijn gegevens die een natuurlijke ordening of rangorde hebben. Het zijn categorische gegevens die gerangschikt of geordend kunnen worden volgens een specifiek kenmerk of eigenschap. Voorbeelden van ordinale gegevens zijn het opleidingsniveau, het inkomensniveau of de cijfers.
- Je kunt nominale gegevens tellen, classificeren en categoriseren, maar niet rangschikken. Aan de andere kant kunnen ordinale gegevens rangschikken of ordenen, maar het onderscheid tussen elke categorie is niet altijd merkbaar of meetbaar.
- Voor nominale gegevens worden taartdiagrammen gebruikt. Aan de andere kant gebruiken ordinale gegevens een histogram of staafdiagram.
Hoe kan QuestionPro helpen bij het beheren van ordinale gegevens?
QuestionPro is een enquêtesoftwareplatform dat enkele functies en hulpmiddelen biedt om onderzoekers en analisten te helpen bij het omgaan met verschillende soorten gegevens, waaronder ordinale gegevens. QuestionPro kan op verschillende manieren helpen met deze gegevens. Hier zijn een paar voorbeelden:
- Enquêtes ontwerpen: U kunt snel vragen maken die geschikt zijn voor het verzamelen van gegevens met de interface voor het ontwerpen van enquêtes van QuestionPro. Je kunt waarderingsschalen, Likert-schalen en andere soorten ordinale antwoordschalen gebruiken om vragen te maken.
- Verzamelen van gegevens: Er zijn veel manieren om gegevens te verzamelen met QuestionPro, waaronder online enquêtes, enquêtes voor mobiele apparaten, enquêtes voor kiosken en enquêtes op papier. Je kunt de beste methode kiezen voor jouw specifieke onderzoeksbehoeften.
- Gegevensanalyse: QuestionPro heeft een set krachtige tools voor het analyseren van gegevens die speciaal voor deze gegevens zijn gemaakt. De software kan bijvoorbeeld de mediaan, modus, bereik, kwartielen en andere beschrijvende statistieken berekenen. Je kunt ook grafieken en diagrammen genereren die geschikt zijn om deze gegevens te visualiseren, zoals boxplots, histogrammen en scatterplots.
LEER OVER: Beschrijvende analyse
- Rapportage: QuestionPro biedt verschillende rapportagemogelijkheden om u te helpen uw inzichten te communiceren nadat u uw gegevens hebt verzameld en geanalyseerd. Rapporten kunnen worden gegenereerd in verschillende formaten, waaronder PDF, Excel en Word, en ze kunnen worden aangepast om alleen de gegevens te bevatten die relevant zijn voor je onderzoek.
LEER OVER: Gemiddelde bestelwaarde
QuestionPro is een krachtig hulpmiddel voor het werken met ordinale gegevens en kan je helpen je gegevens efficiënt en effectief te verzamelen, analyseren en rapporteren.



