




クラスター・サンプリングとは、ある母集団から、均質な特徴を持ち、サンプルの一部となる確率が等しい複数のクラスターを作成するサンプリング方法と定義されています。
ある組織が、ドイツ全土のスマートフォンの性能を調査するシナリオを考えてみましょう。 全国の人口を都市(クラスター)に分け、さらに人口の多い町を選び、モバイル端末を利用している人をフィルタリングすることができます。
クラスター・サンプリングとは?
クラスター・サンプリングとは、確率的なサンプリング手法の一つで、研究者が母集団を複数のグループ(クラスター)に分けて調査するものです。 そこで研究者は、データの収集と分析のために、単純無作為抽出または系統的無作為抽出の手法で無作為のグループを選択します。
例ある研究者が、全米のビジネス教育における2年生の成績を判定するための調査を行いたいと考えている。 すべての大学の学生を対象とした調査研究を行うことは不可能である。 その代わりに、クラスター・サンプリングでは、各都市の大学を1つのクラスターにまとめることができる。 次に、単純無作為抽出または系統的無作為抽出を行い、無作為にクラスターを選んで調査研究を行う。 その後、単純または系統的なサンプリングによって、これらの選択されたクラスターからそれぞれ2年生を選び、調査研究を実施することができる。
このサンプリング手法では、研究者は、人口統計学、習慣、背景など、研究の焦点となりうるその他の集団属性など、複数のサンプルパラメータからなるサンプルを分析します。 この方法は、通常、類似しているが内部的には多様なグループが統計的集団を形成する場合に実施される。 クラスター・サンプリングでは、母集団全体を選ぶのではなく、より生産性の高い小さなグループに二分してデータを収集することができる。
クラスター・サンプリングの種類
このサンプリング手法には、2つの分類があります。 第一の方法は、クラスター・サンプルを得るためにたどった段階の数によるもので、第二の方法は、クラスター分析全体におけるグループの代表性によるものである。 多くの場合、クラスターによるサンプリングは複数のステージで行われます。 ステージとは、目的のサンプルにたどり着くまでの段階を指すと考えられています。 この手法は、1段、2段、多段と分けることができます。
単段階のクラスター・サンプリング:
その名の通り、サンプリングは1回だけ行う。 単段階クラスター・サンプリングの例-あるNGOが、教育を提供するために、近隣の5つの町にまたがる女の子のサンプルを作りたいと考えています。 一段階サンプリングにより、NGOはランダムに町(クラスター)を選んでサンプルを形成し、その町で教育を受けることができない少女たちに支援を行います。
二段式クラスター・サンプリング:
ここでは、クラスターのすべての要素を選択するのではなく、系統的または単純なランダムサンプリングを実施することにより、各グループから一握りのメンバーだけを選択する。 二段階クラスターサンプリングの例 – ある企業経営者が、全米各地にある自社工場の業績を調べたいと考えています。 オーナーは植物のクラスターを作る。 そこで、これらのクラスターから無作為にサンプルを選び、調査を実施する。
多段式クラスター・サンプリング:
多段式クラスター・サンプリングは、2段式サンプリングより一歩も二歩も進んだものです。
複数の地域にまたがって効果的な調査を行うには、複雑なクラスターを形成する必要がありますが、これは多段階サンプリングという手法でのみ実現可能です。 クラスターによる多段階サンプリングの例 – ある組織が、ドイツ全土のスマートフォンの性能を分析するために調査を行う予定である。 日本全体の人口を都市(クラスター)に分け、人口の多い都市を選択したり、モバイル端末を使用している人をフィルタリングしたりすることができるのです。
クラスター・サンプリング実施までの流れ
ここでは、クラスター・サンプリングを行うための手順を紹介します:
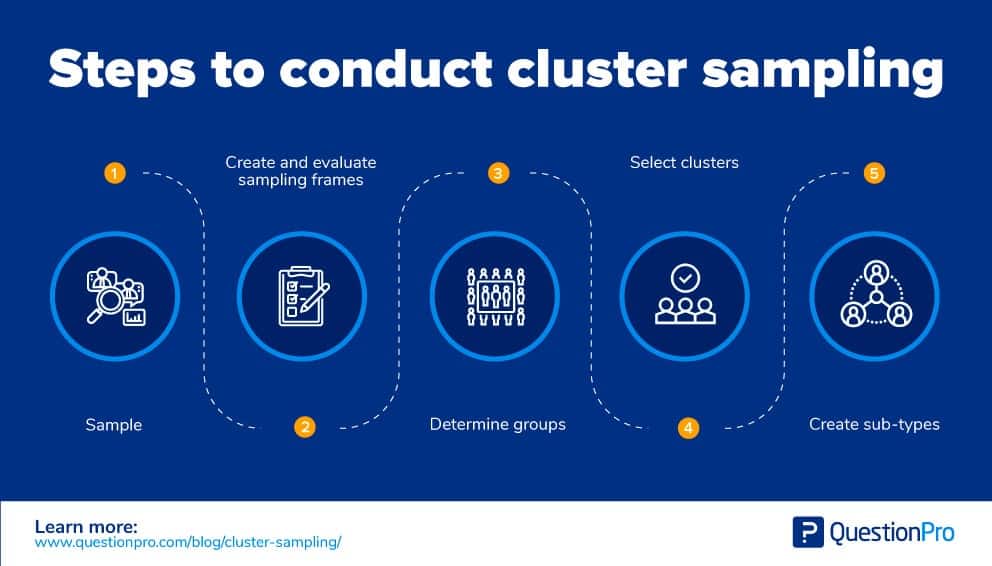
サンプル
対象者を決め、さらにサンプルサイズも決める。- サンプリングフレームを作成し、評価する: 既存のフレームワークを使用するか、ターゲットに合わせた新しいフレームワークを作成することで、サンプリングフレームを作成する。 カバレッジとクラスタリングに基づいてフレームワークを評価し、それに応じて調整する。 これらのグループは、母集団を考慮し、排他的で包括的なものとすることができる、多様なものとなる。 サンプルのメンバーは個別に選択されます。
- グループを決定する: 各グループに同じ平均的なメンバーを含めて、グループの数を決定する。 だから、それぞれのグループの区別をしっかりつける。
クラスターを選択する:
ランダムな選択を適用してクラスターを選択します。
サブタイプを作成する:
研究者がクラスターを形成するためにたどったステップの数によって、2ステージとマルチステージのサブタイプに二分されます。
クラスター・サンプリングの応用
このサンプリング技法は、市場調査のためのエリアまたは地理的クラスター・サンプリングで使用されます。 広い地域は、地域によって分けられたクラスターに送られる調査と比べて、調査費用が高くつくことがあります。 正確な結果を得るためにはサンプル数を増やす必要がありますが、コスト削減により、このクラスター上昇のプロセスは達成可能です。
統計学におけるクラスター・サンプリング
この手法は、研究者が全住民からデータを収集できない統計学で広く使われています。 そのため、研究統計学者にとって最も経済的で実用的なソリューションとなっています。 例えば、ドイツでスマートフォンの利用状況を把握しようとする研究者がいたとします。 この場合、ドイツの各都市はクラスターを形成することになる。 このサンプリング法は、戦争や自然災害の際、居住するすべての個人からデータを収集することが不可能な集団について推論を行うためにも使用されます。
クラスター・サンプリングの利点
クラスター・サンプリングを使用することには、複数の利点があります。 ここに紹介します: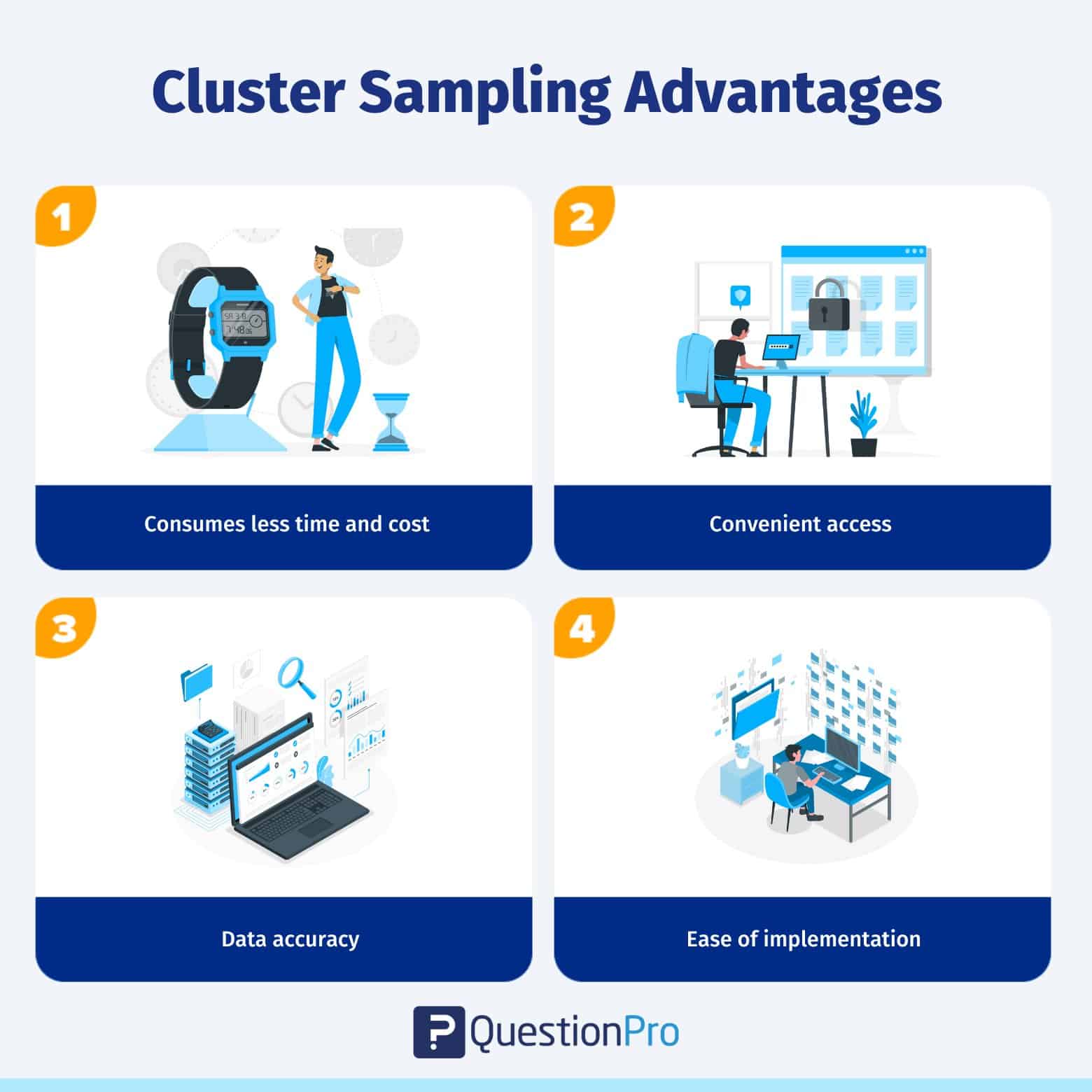
時間やコストがかからない:
地理的に区分けされたグループのサンプリングは、作業や時間、コストが少なくて済みます。 特定の地域全体でランダムに行うのではなく、クラスターを観察し、その選ばれたクラスターに限られた数のリソースを割り当てることで、非常に経済的な方法です。
便利なアクセス:
研究者は、このコンビニエンス・サンプリングの手法で大規模なサンプルを選択することができ、様々なクラスターへのアクセス性を高めることができます。
データの正確性:
各クラスタに大きなサンプルが存在する可能性があるため、個人あたりの情報におけるデータ精度の損失を補うことができる。- 導入のしやすさ: クラスター・サンプリングは、様々な地域やグループから情報を得ることが容易です。 研究者は、他の確率的サンプリング手法と比較して、実用的な場面で迅速に実施することができます。
単純無作為抽出と比較して、母集団などの集団の特性を決定するのに有効であり、研究者は母集団全体のすべての要素のサンプリングフレームを持つことなく実施することができます。
クラスター・サンプリングと層別サンプリング
クラスター・サンプリングと層化ランダム・サンプリングはよく似ているので、その細かいニュアンスを理解するのに問題があるのかもしれません。 そこで、クラスター・サンプリングと層別サンプリングの大きな違いについてお話します:
| クラスター・サンプリング | 層別サンプリング |
|---|---|
| 集団の構成要素は、ランダムに選択され、グループ(クラスター)の一部となります。 | 研究者は、全人口を均等な区分(層)に分割する。 |
| ランダムに選ばれたクラスターからのメンバーは、このサンプルの一部である。 | 研究者は、ランダムに構成される地層の個々の構成要素をサンプリングユニットの一部と見なす。 |
| 研究者は、クラスター間の均質性を保つ。 | 研究者は、層内の均質性を保つ。 |
| 研究者は自然にクラスターを分けていく。 | 層分けは、主に研究者や統計学者が決定する。 |
| 重要な目的は、かかるコストを最小限に抑え、コンピテンシーを高めることです。 | 重要な目的は、適切に表現された母集団とともに、正確なサンプリングを実施することである。 |
結論
QuestionProでは、対象母集団をクラスターに分割して、クラスター・サンプリングを実施することができます。 また、これらのクラスターから無作為にサンプルを選んで調査することも可能です。
QuestionProの堅牢なリサーチツール群には、クラスター・サンプリングの導出に必要なものがすべて揃っています。 そこで、2200万人以上のモバイル対応回答者の中から、お客様のリサーチのために継続的な市場調査研究を行うための回答者を選びます。



