- Galería de imágenes
- Número de preguntas por encuesta
- Creando una encuesta desde un documento de MS Word
- Como editar encuestas en vivo
- Survey blocks
- Aleatorizador de bloques de encuestas
- Question randomization
- Scale Library
- What is monadic testing?
- What is sequential monadic testing?
- Extraction Support for Image Chooser Question Types
- What is comparison testing?
- Custom validation messages
- Survey Builder with QxBot
- Testing Send
- Standard question types
- Advanced question types
- Multiple choice question type
- Text question- comment box
- Matrix multi-point scales question type
- Pregunta de orden de rango
- Image question type
- Date and time question type
- CAPTCHA question type
- Net Promoter Score question type
- Van Westendorp
- Choice modelling questions
- Side-By-Side matrix question
- Predictive answer options
- Presentation text questions
- Multiple choice: select one
- Multiple choice: select many
- Temporizador de página
- Contact information question
- Matrix multi-select question
- Matrix spreadsheet question
- Flex Matrix
- Text Slider Question Type
- Pulgares arriba / abajo
- Rank Order - Drag and Drop
- Pregunta de Matriz Bipolar con escala deslizante
- Bipolar Matrix Likert Scale
- Star Rating Question Type
- Push to social
- Attach Upload File Question
- Constant Sum Question
- TubePulse
- Smiley-rating question
- Homunculus question type
- Closed card sorting question
- Gabor Granger
- Verified Digital Signature
- Video Insights
- Platform connect
- Communities Recruitment
- Reorder questions
- Question tips
- Text box next to question
- Adding other option
- Matrix question settings
- Scale options for numeric slider question
- Constant sum question settings
- Setting default answer option
- Exclusive option for multiple choice questions
- Making a question required - validation
- Bulk validation
- Remove validation message
- Question separators
- Question code
- Page breaks in survey
- Survey introduction with acceptance checkbox
- Question Library
- Embed Media
- Posición de inicio del control deslizante
- Pantalla de respuesta Volteo alternativo
- Validaciones de texto
- Answer type
- Text question settings
- Image rating question settings
- Budget scale question settings
- RegEx Validation
- Matrix - Auto Focus Mode
- Numeric Input Settings- Spreadsheet
- Answer Groups
- Hidden Questions
- Decimal Separator Currency Format
- Allow Multiple Files - Attache/Upload Question Type
- Text box - Keyboard input type
- Deep Dive
- Add logo to survey
- Custom theme using CSS
- Auto-advance
- Progress bar
- Automatic question numbering option
- Enabling social network toolbar
- Print or download survey
- Atrás | Salir - Botones de navegación - ¿cómo hacerlo?
- Visual Display Mode
- Display Settings
- Browser Title
- Survey Navigation Buttons
- Accessible Theme
- Focus Mode
- Survey Layout
- Telly Integration
- Telly Integration
- Workspace URL
- Classic Layout
- Lógica de salto
- Lógica de ramificación compuesta
- Compound or delayed branching
- Dynamic quota control
- Texto dinámico - caja de comentarios
- Lógica de extracción
- Lógica de mostrar / ocultar pregunta
- Mostrar / ocultar dinámico
- Lógica de scoring
- Net promoter scoring model
- Piping text
- Encadenamiento de encuestas
- Looping
- Ramificación al finalizar una encuesta
- Logic operators
- Block Flow
- Bloque de looping
- Scoring Engine: Syntax Reference
- Matrix Extraction
- Advanced Randomization
- Custom Scripting Examples
- Selected N of M logic
- JavaScript Logic Syntax Reference
- Always Extract and Never Extract Logic
- Locked Extraction
- Dynamic Custom Variable Update
- Survey settings
- Guardar y continuar
- Anti Ballot Box Stuffing (ABBS) - disable multiple responses
- Deactivate survey
- Admin confirmation email
- Action alerts
- Survey timeout
- Finish options
- Spotlight report
- Print survey response
- Search and replace
- Compact view
- Survey Timer
- Allowing multiple respondents from the same device
- Admin Confirmation Emails
- Geo coding
- Barra de progreso clásica | QuestionPro Help Center
- Limitación de respuestas
- Text Input Size Settings
- Survey Close Date
- Respondent Location Data
- Review Mode
- Review, Edit and Print Responses
- Age Verification
- Live survey URL
- Customize survey URL
- Create email invitation
- Personalizing emails
- Email invitation settings
- Email list filter
- Email list filter
- Survey reminders
- Export batch
- Email status
- Spam index
- Send surveys via SMS
- Phone & paper
- Adding responses manually
- Embedding Question In Email
- Eliminar listas de correo electrónico
- Distribución de encuestas multilingües
- Mejores prácticas para envíos de correo electrónico
- SMTP
- Domain Authentication
- QR Code
- SMS Pricing
- Reply-To Email Address
- Email Delivery Troubleshooting
- Survey Dashboard - Report
- Overall participant statistics
- Dropout analysis
- Banner tables
- Análisis TURF
- Análisis de tendencias
- Correlation analysis
- Survey comparison
- Gap analysis
- Mean calculation
- Weighted mean
- Spider chart
- Dashboard filter
- Heatmap Analysis
- Data Quality
- Cluster Analysis
- Datapad
- Download Options - Dashboard
- HotSpot analysis
- Weighted Rank Order
- Cross-Tabulation Grouping Answer Options
- A/B Testing in QuestionPro Surveys
- Data Quality Terminates
- Matrix Heatmap Chart
- Column proportions test
- Diseños de análisis conjoint
- Conjoint part worths calculation
- Importancia del análisis Conjoint
- Conjoint profiles
- Market segmentation simulator
- Conjoint brand premium and price elasticity
- What is MaxDiff scaling
- MaxDiff settings
- MaxDiff FAQ
- Conjoint calculations and methodology
- Anchored MaxDiff Analysis [BETA Release]
- MaxDiff- Interpreting Results
- Automatic email report
- Import external data
- Download center
- Consolidate report
- Delete survey data
- Exporting data to Word, Excel or Powerpoint
- Scheduled reports
- Dataset
- Notification Group
- Data quality - Patterned responses
- Data quality - gibberish words
- Data quality - All checkboxes selected
- Unselected Checkbox Representation
- Merge Data 2.0
- Plagiarism Detection
- IP based location data
- Update user details
- Update time zone
- Business units
- Add Users
- Usage dashboard
- Single user license
- License restrictions
- Inicio de sesión
- Software support package
- Roles de usuario personalizados
- Agregar usuarios de manera masiva
- Two-Factor Authentication
- Welcome Email
- Network Access
- Changing ownership of the survey
- Unable to access Chat support
- Navigating QuestionPro Products

Parte de Valores- Análisis Conjunto
Esto significa niveles de utilidades para los atributos de un conjunto. Cuando atributos múltiples describen juntos el total del valor del concepto de un producto, la utilidad de las partes de valores separadas del producto (designadas a los atributos múltiples) son parte-valores.
Nosotros usamos el siguiente algoritmo para calcular el CBC del Conjunto de los Valores de la Partes:
- NOTACIÓN
Permita que sea la R de encuestado, con la r de individuos = 1...R
Permita que cada encuestado ve las funciones T, con t = 1 ...T
Permita que cada función T tenga Configuraciones C (o conceptos), con c =1 ...C (la letra C es usada para número 3 o 4)
Si tenemos atributos A, a = 1 de A, teniendo en cada atributo el nivel LA, l =1 a La. Después el valor de la parte para a
Los atributos particulares/nivel es w’(a,l). si esto es (conjunto irregular) de valores de partes, estamos resolviendo este ejercicio. ¡Nosotros podemos!
Simplifica esto a un conjunto dimensional w(s), en donde los elementos son:
{w’(1,1), w’(1,2) ... w’(1,L1), w’(2,1) ... w’(A,LA)} con w teniendo elementos S.Una configuración específica x, puede representar un conjunto de dimensión x(s), donde x(s)=1 si lo especifica
nivel/atributo es dar, y de lo contrario es 0.
Permita que Xrtc represente la configuración específica de la configuración cth en la tarea tth para el encuestado rth. Por lo tanto
el diseño del experimento es representado por cuatro dimensiones de matriz X con tamaños de RxTxCxS
Si los encuestados r escogen un configuración c en la tarea t, entonces permita que el 1=Yrtc; de lo contrario a 0.
- UTILIDAD DE UNA CONFIGURACIÓN ESPECÍFICA
La Utilidad Ux de una configuración específica es el resumen de una parte de valor para esos atributos/niveles presentes en la configuración, i.e. esto es el producto escalar x.w.
- EL MODELO LOGITO MULTI-NOMIAL
Para una elección simple entre dos configuraciones, con utilidades de U1 y U2, entonces el modelo MNL predecirá que la configuración 1 será la elegida
EXP(U1)/(EXP(U1) + EXP(U2)) del tiempo (un número entre el 0 y el 1).
Para la decisión entre las configuraciones N, la configuración 1 será elegida
EXP(U1)/(EXP(U1) + EXP(U2) + ... + EXP(UN)) of the time.
- PROBABILIDAD DE ELECCIÓN MODELADA
Permita que la probabilidad escogida(usando el modelo MNL) de selección de la configuración cth en la tarea tth para el encuestado rth sea:
Prtc=EXP(xrtc.w)/SUM(EXP(xrt1.w), EXP(xrt2.w), ... , EXP(xrtC.w))
- MEDIDA DEL REGISTRO-PROBABILIDAD
La medida del registro de probabilidad LL es calculado como:
Prtc es una función del vector w de la parte del valor, el cual es el conjunto de las partes de valores que estamos resolviendo.
- RESOLUCIÓN DE LAS PARTES DEL VALOR UTILIZANDO UNA PROBABILIDAD MÁXIMA
Nosotros resolvemos para el vector de la parte de valores, buscando el vector w que te da el valor máximo de LL que estamos resolviendo para la variable S.
Esto es un problema multi-dimensional, continuo no-lineal ; requiere solucionar estándar. Nosotros usamos el Nelder-Mead Simplex Algorithm.
La función de la probabilidad-registro deberá ser implementada como una función LL(w, Y, X) y luego optimizada para encontrar el vector w que nos da un máximo. Las respuestas Y y el diseño X, se darán, contrasta una optimización específica. El valor inicial para w se puede ser el conjunto del origen 0.
El final de la parte de los valores w esta remodelada, así los valores de las partes para ningún atributo tienen el significado de cero, simplifica restando el significado de la parte de los valores para todos los niveles de cada atributo.
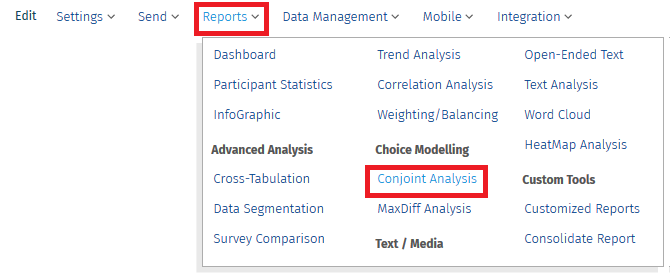
Para Ver las Partes de los Valores
Ve a:
- Login » Surveys » Reports » Choice Modelling » Conjoint Analysis